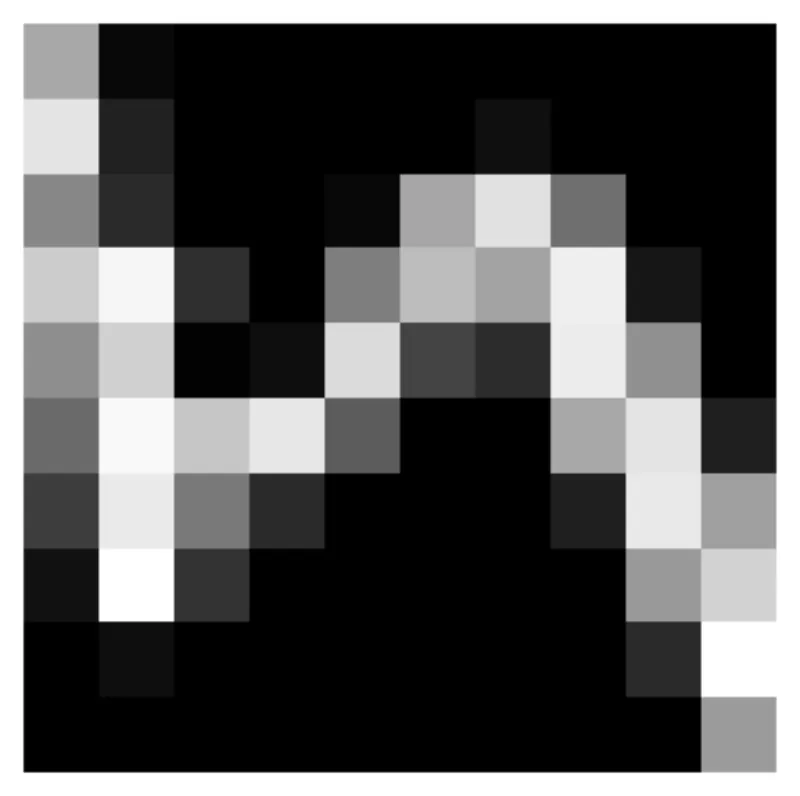Thus another NeurIPS has ended. This is the third one for me, and for every one
I've attended I feel it has increased in size. I reflect on my experience this
time around. Some context: I have just finished my PhD and I'm on the job market
looking for a job, ideally ML research in industry. While the main reason I went
is to present my paper, I also attended in order to see what the job market is
currently like and make some connections with companies and researchers in
industry and academia.
I presented our approach (which we call MEKRR, "maker") on how to successfully
transfer pretrained GNNs for learning to predict energies of atomistic system.
This combines GNN feature representations with kernel mean embeddings and ridge
regression. Do have a look at the arxiv paper (will update this link with the
conference paper once it's been made available in the official NeurIPS
proceedings) or the code base :)
I will write more about MEKRR in a separate note and will link it here later.
The gist of it is that using learned features from GNNs on trained an upstream
dataset and using KRR on these features, together with some kernel tricks for
dealing with sets / point clouds, works really well. Will kernels make a
come-back? Probably not. Can kernels improve performance on small to medium
size datasets when given a strong feature map when compared to fine-tuning? Probably yes!
The expo hall was bustling. My sense is that the companies can be categorized
into
big Tech such as MAMAA (previously known as FAANG) and some older tech
companies such as IBM,
trading companies such as Jane Street or DE Shaw,
lots of smaller companies serving LLMs and other models as a service, or
speeding up inference using quantization and other postprocessing techniques,
the rest which includes peripheral companies using ML (Sony, Disney), biology
/ drugs / medicine and publishing houses.
In general it was a pretty good place to get in touch with companies. I made
some really good genuine contacts which I will cherish whether it'll lead to job
or not. I disliked talking to recruiters which in the end just forward me to the
general recruitment page of their companies, feels like a waste of time on both
their and my part.
Go through all booths on the expo day instead of spacing it out over the week
Get over fear of talking and engage with people instead of circling around
wasting time
Tip: Use the booths which you are not really interested in or have low
engagement to warm up. It's fun to see what people are up to and they
probably enjoy people actually talking to them.
I spent a couple of hours each day going through the hall in a systematic manner
(my wife remarked that I had so much good swag, mostly really high-quality
socks, which can be explained simply by going through almost every booth…).
I think this is worthwhile but drains your energy and takes up a lot of time.
Looking back I wish I just had done this during the Sunday when I arrived so
that I could have focused on the posters and talks on the other day. This time I
didn't spend much time at all on the research part of the conference which I
slightly regret. But I met with the companies and engaged in some way or another
with about 80% of the booths which I count as a success.
Another part is getting over yourself and just talk to people. At the start of
the conference I was quite shy and wondering why people would want to engage
with me, but honestly, the whole reason for these companies to be present at
NeurIPS is to talk to the attendants (even if the chat does not actually lead
anywhere) at least out of courtesy. I should work on overcome this fear and just
throw myself out there. Talking to low-stakes companies first help to get over
this barrier I felt.
I went to a couple of parties which was great. Good time to reconnect with
people I haven't seen in a while and connect with new people. One party was
thrown by one of the UK initiatives for AI Safety and it was interesting
chatting about the state of things. Seemed like the onus was on first making
people aware of the problem and in what ways it can be approached and
potentially solved, working similarly to a think-tank. After this party ended we
went to the Cohere party which was thrown in this amazing multi-layered
building, really cool party, would go again.
While the above party was more general and open, I also went to an open bar
hosted by Imbue. This was super cozy and intimate. I made some great contacts
there and spoke to many of the people in the team. The party was hosted outside
of the usual district which probably made it so less people attended, but on the
other hand, the people there really were there for a reason. I thoroughly
enjoyed myself, one of the highlights of the conference for me.
LLMs where everywhere. I don't think this should have come as a surprise to
anyone. In one sense I feel like ChatGPT and it's kind has been the first to
actually deliver on the promise of AI to the consumer (at least during my
lifetime, would be interested to here contrasting viewpoints) so it's only
natural that research will tail this development as we have a pretty poor
understanding on what actually goes on inside of these models. On the other hand
there's the question of what the role of academia and publishing should be, to
always cater to industry or to do high-risk research which enables the Next Big
Thing (TM)? Pretty hard to do this kind of research when a lot of it comes down
to compute.
Presenting my poster was a blast. We had a lot of activity and I had great
feedback. Someone even came and wanted a selfie with me and the poster! This is
the highest flattery I've ever received in my academic career by far. There were
some senior researchers that found this work interesting and really engaged with
me. This cemented my confidence in this line of work and I hope that others will
continue investigating how kernels can fit into a neural network world.
Since I've been lazy and not written update for RC Week 5 and 6, I decided to
ease the burden and roll them both into a half-batch retrospect instead so that
I can bring myself to actually write it and reduce friction-to-write.
When I plan my days I have a lot of tasks that I would like to get finished,
alas, at the end of the day, most of these tasks remain unfinished. I need to be
more realistic. Additionally, I should do some meta-planning where I use certain
days for certain related tasks instead of having many unrelated tasks (e.g.
mixing admin with writing code and reading papers). This is something that I
continue to work on.
I had a chat with some of the RC admin about how it has gone so far. It was
super chill but very insightful. While some things have not gone as I wanted
(does anything ever go according to plan? Don't think so!) it was reassuring to
get some outside point of views which also highlighted what I did accomplish,
like setting up this website and the more meta-skills of building volitional
muscles etc.
Removed a lot of coffee chat slots, limiting them to just Fridays from now on. Think I need to go more into deep work mode.
I think this sets the tone for the later part of the batch for me. The social
aspect of RC has been great fun and I've made loads of friends and connections,
but it takes energy and janks you out of your flow doing all of these scheduled
coffee chats. Once per week will be enough from here on.
I will focus less on the social aspects of RC and more on getting
better at coding. I want to finish my project before the end of batch, and if I
do it before that I want to maybe try to create a Jax package. Here's to the next year and the next RC batch!
I managed to get my workstation set up properly. Now I have a beefy gpu which I
can use on-demand from my laptop. I also went a bit crazy and set up a VPN so
that I can use jupyter together with emacs. For this I relied a lot on this blog
post on emacs and jupyter which saved me many hours. I found the code-cells
emacs package to be very well-engineered and striking a good balance between
light-weight and feature complete.
This is a long overdue retrospect of my time at RC. I've been super busy with
job searching and preparing, but the other day I looked at the niceties sent out
to me by email, and it filled me with absolute joy (thanks to all who wrote
them, it really made me a little bit teary-eyed and emotional 🥲).
We have the hub in Brooklyn. This is the physical place of RC. But RC is so much
more than that, and it's also not static, but a changing living entity. Certain
things change more slowly, like the hub and the tools we use together with the
spectacular and kind admins. Other things do change rapidly (almost, like, every
6 weeks… 1). Being out of batch and still going to the hub it feels..
different. Not in a bad way, but being out of batch and seeing so many new
people is great, but also weird. Life moves on, people never-graduate and may
not be around in the same way as before. The context change.
RC is a context. Each batch is its own context with different people coming from
different backgrounds with different personalities and tastes. Each batch is big
enough that I would say the average stays reasonably similar from batch to
batch, but to be clear, RC is not about averages, it's about the individual
connections you make and the context you bring to your batch. From my own point
of view, RC was a perfect thing to do while I wait for my employment
authorization to come through. But really, it has shown to be so much more than
that. RC is and was a social context for me in New York. Somewhere to go and
hang out, interact with others and learn new things in an open and warm
environment.
RC is remarkable. I think it attracts a certain kind of people wanting to become
better programmers and learn new things for the joy of it, rather than pure
career progression (although one may lead to the other, the other way around
maybe not so much). The directives are pretty clear: work at the edge of your
abilities, build your volitional muscles and learn generously. But as much as RC
asks you to apply these self-directives, I think there is a feedback loop the
other way around, where the context allow you to apply these successfully.
RC as a place and context has allowed me to learn many things, make many friends
and understand better what I want from a social technology context.
My focus shifted wildly during my batch. For my application I wrote that I
wanted to implement a machine learning library using scheme 2. I quickly let go
of this idea and proceeded to socialize and get in the groove of the RC spirit.
For a large part of the first half of my batch I did a lot of coffee talks,
learned about HTML and CSS and how to use org-mode and emacs to create this
blog. A personal reflection is that I can be pretty harsh on myself. Looking
back at my previous RC notes ( RC-week-1.html, RC-week-2.html,
RC-week-3.html, RC-week-4.html and RC-halfbatch.html) I summarize
them below.
First off, I thought that my web-development learning would be swift and I would
go on to do "bigger" things. In reality, this part took longer, on the other
hand, I actually built this website by hand (a labour of love!) and in itself
that is something beautiful. My main project (which did not materialize at the
end during the batch, but I have some vague sense that this will be finished in
the future) started forming in my mind early and I still have the data around. I
did not finish it. I did do several presentations and non-presentations, but
could maybe have done better. However, I did still present! Looking at the
presentations have really been inspiring to me, enforcing the rule of learning
in the open and sharing what we've learned.
For impossible day I learned to how to use flask to set up a web-server which
was great. Got into the weeds on how to use databases, minimal html and elements
used for functionality through flask. One more step to becoming a full-stack ML
developer (I jest.. or?). This was a step forward, but I still felt a bit
unfocused. As a side-project I learned some algorithms and data structures, and
I can say that this has actually been a success and will hopefully help me land
a job soon.
A thing I did not go into much was that I levelled up my toolsets and personal
workflow. I will probably make a note about this later but in short
Fixed a satisfactory org-mode + jupyter kernel workflow which actually works.
Set up a VPN so I can connect to devices on my home network, which allowed for
the above computational notebook to actually be possible in the first place.
Bought a GPU and installed it.
All in all a great outcome, and possibly in the spirit of RC?
I also learned Jax and Diffusion models, together with some mechanistic
interpretability, mostly for the family of LLMs and transformers. This was lead
by the great Changlin Li. Dipping into ML in this way has been great and
re-ignited a passion again.
So where does this leave us (me)? Three months seem long, but it's short.
Chipping away day-by-day is the only way to keep going though and does lead to
returns, essentially yielding cumulative interest on what you have learned and
you knowledge. I feel like a more apt and capable technologist and understand
how computers work better and how to use the web to share more openly. This was
one of my goals coming into RC so this has been a great success. And this by
itself made RC worth it.
I will stick around, at least for the foreseeable future. I will also hang
around on the Zulip, so if you want to reach me, either email me (you can find
my contact in the footer) or reach out on Zulip. I promise I won't bite 😄.
I just started the winter 1 batch of 2023 at the Recurse Center (RC)! I'm very
happy, I wasn't sure that I was going to make it as I applied very late and
worried that I would miss the deadline for this batch. However, the process went
super smooth and here I am at then end of week 1 (actually start of week 3, but
I just now got my website up and running).
I will be keeping notes on RC here, mostly weekly retrospects where I will
reflect and potentially plan for the coming week together with short updates
about what I'm doing.
RC operates a truly hybrid retreat where participants come from all over the
world (and timezones). As of writing this (day 2 of week 3, I'm a bit out of
sync but aim to catch up to my current day soon!) I am in Sweden as I am sorting
out my visa. Week 1 was split into two sections as the hub wasn't opened for the
Winter 1 2023 (or just W1'23 batch) until the Wednesday of this week. So Monday
and Tuesday were remote while the rest of the week I was present in the hub.
I think this format really works well, since it is designed with being hybrid in
mind and not tacked onto an already existing model. I think the tools really
help here as I find Zulip a joy to use once you get the hang of it compared to
for example Slack and the virtual RC hub is fun and interactive. However, being
physically in the hub is also great, the space is very cool and inspiring (it
really has a nice, comfy hacker vibe).
This week was spent mainly getting to know people of the batch, who they are,
what they do and what their plans were. According to the directory of
participants of my batch we are 45 people and additionally there are people
from the previous batch who are also around, making it 93 people in total. The
directory really helps keeping track since I can study who I met and do some
quick mental notes, but I have several times re-introduced myself to others at
the hub.
I think taking an organic approach to this is best
Try to meet as many people as you can.
Go to events and be ready to try new things out
Introduce yourself even if you may not have the time to chat properly as
this will set a context for further interaction and make it less awkward to
talk
Don't worry about meeting everyone, just be nice and things will sort itself
out in time
Naturally you will gravitate towards some people, either due to vibing or just
because you share similar interests. However, don't let this make you insular,
form inclusive contexts rather than insular cliques
Typing out the above it also strikes me that everyone present has a
responsibility to make this retreat inclusive and enjoyable. This is basically
some additional aspirations in addition to the RC social rules.
RC has an online manual which lays out what
RC is, the environment and how to make the most out of your batch including
logistics, planning your stay and the philosophy of this
unusual experience. The manual
contains a lot of material, but I found it really comprehensive and great for
setting the tone for the retreat. In any case, it can be used as a reference as
you go through your batch.
There are also other resources available internally which I've found really
helpful such as the directory of nevergraduated RC alumni. The wiki is great and
contains a lot of project that previous RC people have created.
Finally, I think it's so refreshing to have things written down. Often we don't
find the time to actually document processes, which leads to repetition which
can become tiring, or worse, we may be uncertain what processes are or they may
be implicit.
At the end of the first week I felt excited, a bit overwhelmed, and slightly
anxious about what my project would be. The
self-directives were mentioned a
lot and we also did some exercises about building our volitional muscles which I
appreciate since I have a tendency to become a bit paralyzed when trying to
scope out new projects and I should just get to it rather than just doing
background reading perpetually!
It was a joy to meet everyone during the first week and looking forward to
meeting more people in the coming week, working together on different projects
and pair programme!
This week I kept talking and meeting with people, a combination of scheduled
talks and impromptu meetings in the hub and especially the kitchen (especially
especially the coffee machine). I found the coffee bot to be a good way of
having an opt-in coffee chat with people that you haven't met yet, or to get to
know others better that I've already introduced myself to.
I'm continuing to be impressed and happy about the pure breadth and diversity of
people in terms of background and talents. It's really great to get to know what
people are working on and realizing further fields which you may not even know
exist and / or know about but have to real clear picture of. I hope I'll be able
to meet everyone in my batch by the end of the retreat.
During this week I started learning about web development, HTML and CSS, in
order to build this website and have somewhere to publish my notes. I've started
this several times in the past but never gotten to the finishing line, so I see
this as a success in itself, a small win for me to get started.
I will not go into the technicalities of this website and how I've decided to
structure my notes and pages. For a note on this, see my note on how I build
this website!
During this week I had an idea which came to me, where I will build a "this RC
does not exist" 1 by taking photos of the hub and then fine-tune an image
generative model on this dataset. I already know a lot of machine learning, but
generative modelling has never been one of my fields of focus.
I am excited about doing this project as it would allow me to do a full
ML-pipeline from data collection all the way to a user facing website serving
images. Let us see how this goes. I have already started collecting some images,
so it's a start!
There are so much you could potentially do at RC. It's easy to form study groups
or hold events around almost any topic of choice. It's a real smorgasbord of
opportunity, to dive deep in topics you already know or pick up something new
and go from beginner to intermediate in 3 months. Of course, the effect of
focusing on too many things is that you will not get too far into any one topic
in addition to taking energy and time from actually working on projects.
During this week I realized that I cannot attend everything and that I should be
a bit more mindful where I spend my time and energy in order to finish a project
before the end of the batch. Some events I want to attend from time to time even
though it may not be related to my area of expertise (like the creative coding
session where we code something in 90 minutes using a small prompt to work the
creative muscles), but others I will have to leave for now as otherwise I will
spread myself too thin.
I moved to NY just a couple of months before RC started. In order to get settled
I need to fix my J2 visa as my partner has a J1 visa already. To do this I had
to return to Sweden (where I am currently in the area of Malmo and Lund where
some of my siblings live). While it's been great seeing family it has been
harder to stay focused on the RC batch mostly due to having to find a new
routine being fully remote.
Some of the things I think is different
It's much harder to meet new people since you actively have to reach out or
use the RC virtual space rather than randomly meeting people in the kitchen
of the hub.
With people around I can use their energy to energize myself, and I didn't
realize how much this was a thing until I went to Sweden.
Generally, contacting people to pair programme and other activities just have
a bit higher friction which tires me out more.
I'm on vampire-time where I stay up until 05:00 and get up around 12:00.
Next week I will see if I can come up with ways to mitigate these points.
I don't think I'm a very good presenter, but I think I could be. One of the aims
that I have with RC is to overcome my (not super big) anxiety of speaking and
giving talks and presentations. My goal for the rest of the batch is to give a
presentation at least once a week. This weeks presentation was a small intro to
how meditation is often categorized in a Buddhist setting, I use reveal.js which
outputs to html so I will try to put the slides I generate throughout RC on this
webpage somehow!
I've paired with several people at this point and I really enjoy it. It's a bit
of a double edged sword as it can really drain you since your pairing partner
usually keeps you focused on the task and subjectively it feels like you engage
your system 2 more than your mindless system 1. I think that on the whole this
reduces the work needed in the end and also add a nice social aspect to coding!
This week we did the so called "impossible day" where we set our goal on doing
something impossible, that is, outside of what we expected to be able to do.
I've slowly getting to grip with web-development, and wanted to make a
side-project to my generative ML project where I want to generate novel images
of the RC hub in the form of an online portal where people could upload images
of the hub which I store in a database. Just days before we had gotten $100
credits at render.com which I wanted to use to improve my understanding on how
to actually build a functioning web-app and deploy it and make it available
using a Recurse sub-domain. Here is the resulting website!
With some help from some good web-dev people through pair programming I actually
managed to get something together and deploy it successfully (although extremely
bare-bones and barely working). All in all, I managed to
This week was a bit all over the place. I felt like I got some things done, but
on the other hand I also felt like I lacked some focus with respect to the
project. Often I feel that I overestimate what I can get done in a day; I see
this in my daily checkins as I often have several points in my todo list for
that day which are not ticked off due to unforeseen issues, social meetings or
events. At the very least I usually tick some off which is still a win, but it
makes me wonder if I should just internalize this and make my estimations more
accurate.
I also wonder if I'm maybe being too hard on myself. Yes, there are some things
which if I worked harder would have completed, but also I did other things (such
as the above social meetings and events) which also feel important. Finding the
balance between things is just inherently hard I believe!
Slowly this project is ramping up and this week was interesting as I got to
learn some new data science tools I haven't worked with before. The dataset I
have collected comes without labels as I collected it myself, so I thought I
should also label it for whatever downstream task I decide to use it for. I
settled on the Label Studio python library which seems very powerful and lets
you define your own annotation UI through XML (I've been learning HTML / CSS for
this website, so using XML was not as much of a pain as I thought it would be).
The dataset now consists of about 350 images from around the hub, many of them
images of signs or text which I will try to fit a generative image model to.
Here are some example images
Figure 1: A sign of 5, looks a bit industrialFigure 2: Some really old computers from the hub
I've been following the MIT 6.006 course as I never had a proper introduction to
algorithms before, which I felt has been holding me back when programming as I
did not have a good grasp of more fundamental algorithms (sorting, shortest
path, etc.) and data structures (arrays, dictionaries, sets, etc.). I'm really
enjoying myself so far, a bit more than halfway through the course.
In addition to the above I've been slowly doing LeetCode problems together with
some other RC attendants and it's been great fun. Hope to get some more problems under my belt and tackle medium and hard in due time!
]]>https://isakfalk.com/notes/RC-week-4.html2024-02-26T10:47:00-05:00Building this websiteIsak Falk
What spurred me to redo my website and blog is the fact that I got accepted to
RC and they encourage us to learn openly. This is something that I've wanted to
do for a long time anyway, so I felt that now is the time to get this website up
and running.
Basically, I know nothing (or very little) about web development, and would
like to get up to speed where at least I am comfortable adjusting my website.
I plan on using emacs to the extent possible, and I'll put the source of how I
build the website together with the source of the actual notes and static
pages + assets online at src.hut and eventually building it there.
Each org mode file will have some options relating to information which will be
taken care of when the site is published. In practice, this means that the
resulting HTML will take into account this options somehow.
There are great blog posts of what diffusion and score matching is elsewhere, in
particular, see Lilian Weng's literature review and the great exposition of Yang
Song on learning score functions for generative modeling. Here I will mainly
lean on the blog post of Yang Song and his and his collaborators paper
Generative Modeling by Estimating Gradients of the Data Distribution
( Song and Ermon 2020) as I find it very comprehensive and
well-written.
Some of the sections are pretty technical, for the actual implementation you
only need to
Understand how the loss \(\ell(\theta; \sigma)\) defined in
\ref{eq:simplified-score-matching-objective} is used to build the optimization
objective \(\hat{\mathcal{E}}(\theta; (\sigma_{l})_{l=1}^{L})\) defined in
\ref{eq:aggregated-final-empirical-risk} which we train on to produce the
estimator \(\hat{\theta}_{n}\) which are the learned parameters of the score
network \(s_{\theta}\),
Read the Generating samples section to understand how to generate samples using \(s_{\hat{\theta}_{n}}\),
To start with, we assume that we have a dataset of iid samples
\((x_{i})_{i=1}^{n}\) sampled from some unknown data distribution \(p^{\ast}\),
where the datapoints live in some space \(\mathcal{X}\) which we will take to be
some Euclidean vector space (for example, \(\mathbb{R}^{D}\) for a vector or
\(\mathbb{R}^{H \times W \times C}\) for an image with width \(W\), height \(H\)
and \(C\) color channels). Everything is nice so we assume that \(p^{\ast}\) has
a pdf and identify the distribution with this pdf (so \(p^{\ast}(x)\) is the
density at \(x\)). The goal is to learn a model which would allow us to sample
from \(p^{\ast}\). One way to do this would be to model \(p^{\ast}\) directly,
but as fortune has it, it is enough to learn a model of the score function
\(s^{\ast}(x) = \nabla_{x} \log p^{\ast}(x)\) to accomplish this.
Learning the score function using score matching allows for much easier training
and modelling than trying to learn a model of \(p^{\ast}\) directly. This is due
to not having to learn a properly normalized distribution but only up to a
constant. If rewrite \(p^{\ast}(x) = \exp(-f^{\ast}(x))/Z^{\ast}\), the score function takes
the form \(-\nabla_{x} f^{\ast}(x)\) since \[ \nabla_{x} \log p^{\ast}(x) =
-\nabla_{x} f^{\ast}(x) - \nabla_{x}\log Z^{\ast} = -\nabla_{x} f^{\ast}(x) \] as \(Z^{\ast}\)
is independent of \(x\).
where \(s_{\theta}: \mathcal{X} \to \mathcal{X}\) is a model of the score
function, for example a neural network. Of course, we don't know \(s^{\ast}\) so
this objective is not very good, but it can be shown to be proportional to
In practice, we replace the distribution \(p^{\ast}\) by the empirical version
\(\hat{p}_{n}\) using the train dataset \((x_{i})_{i=1}^{n}\). When the input
dimension is large the trace computation becomes too computational burdensome so
we rely on other approximation. We will use denoising score matching, but there
are other ways, in ( Song and Ermon 2020) they also
mention sliced score matching as an alternative.
To get to the point, denoising score matching replaces the distribution
\(p^{\ast}\) with a smoothed version \(q_{\sigma}(x) = \mathbb{E}_{X' \sim
p^{\ast}}\left[q_{\sigma}(x|X')\right]\) where \(q_{\sigma}\) is a some
symmetric bell-curved distribution, for example a gaussian with standard
deviation \(\sigma\) and mean \(X'\). Intuitively the scale parameter \(\sigma\)
allow us to trade off some bias for variance by interpolating between the true
(empirical) distribution as \(\sigma \to 0\) and a uniform distribution as
\(\sigma \to \infty\) 1, in addition to making training possible as it makes
the resulting smoothed empirical distribution have full support on
\(\mathcal{X}\) (so, it is never zero anywhere). Without this smoothing,
\(\hat{p}_{n}\) will always be zero on points outside of the train set which
comes with all kinds of problems. Choosing \(q_{\sigma}(x | x')\) to be an
isotropic Gaussian pdf / distribution with covariance matrix \(\sigma I\) and
mean \(x'\) simplifies objective \ref{eq:tr-score-matching-objective} to
where both the risk \(\mathcal{L}\) and the score model \(s_{\theta}\) are now
indexed by \(\sigma\). We may think of this as parameterizing a family of score
models by \(\sigma\) for some fixed \(\theta\). Let's call the empirical risk
\(\ell(\theta; \sigma)\) where we replace \(p^{\ast}\) with the empirical
distribution \(\hat{p}_{n}\). The final objective defining the Noise
Conditional Score Network above average losses over a geometrically spaced grid
of scales \(\sigma\). For such a grid \((\sigma_{l})_{l=1}^{L}\) we have
where \(\lambda\) is some weighing function which we will fix to be \(\lambda(\sigma) = \sigma^{2}\)
according to the heuristic in ( Song and Ermon 2020). Let us call the learned parameters \(\hat{\theta}_{n}\).
We can use Langevin dynamics to produce samples from the learned score model \(s_{\hat{\theta}_{n}}\).
Usually, Langevin dynamics allow us to sample from some distribution \(p\) as
long as we can evaluate the score function \(\nabla_{x} \log p(x)\). Fixing a
step size (or more generally, a schedule) \(\eta\) and some prior distribution
\(\pi\) we can sample an initial value \(x_{0}\) and iterate using
where \(Z_{t}\)'s are sampled iid from a unit Gaussian. Replacing
\(\nabla_{x}\log p(x)\) with \(s_{\hat{\theta}_{n}}(x)\) we can generate samples
hopefully resembling those from \(p^{\ast}\).
More generally, for any procedure which produces samples from a distribution
\(p\) using only the score function, we can plug-in \(s_{\hat{\theta}_{n}}\) which
we've learned and produce samples, using the plugin-estimator method.
This is pretty nice, we can tap into all the work which has been done in the
field of MCMC 2, for example Hamiltonian Monte-Carlo or NUTS. The decoupling of
training and inference leads to many benefits, as we can repurpose
\(s_{\hat{\theta}_{n}}\) for other downstream tasks.
import functools
import math
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_style( "white")
import jax.numpy as jnp
from jax import grad, jax, vmap, lax
from jax import random
from jax import value_and_grad
import jax.tree_util as jtu
import jax
import equinox as eqx
import optax
from jaxtyping import Array, Float, Int, PyTree
import tensorflow_datasets as tfds
from tensorflow_probability.substrates import jax as tfp
tfd= tfp.distributions
tfb= tfp.bijectors
tfpk= tfp.math.psd_kernels
2024-02-05 13:35:57.262064: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-02-05 13:35:57.262106: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-02-05 13:35:57.263175: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-02-05 13:35:58.023617: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
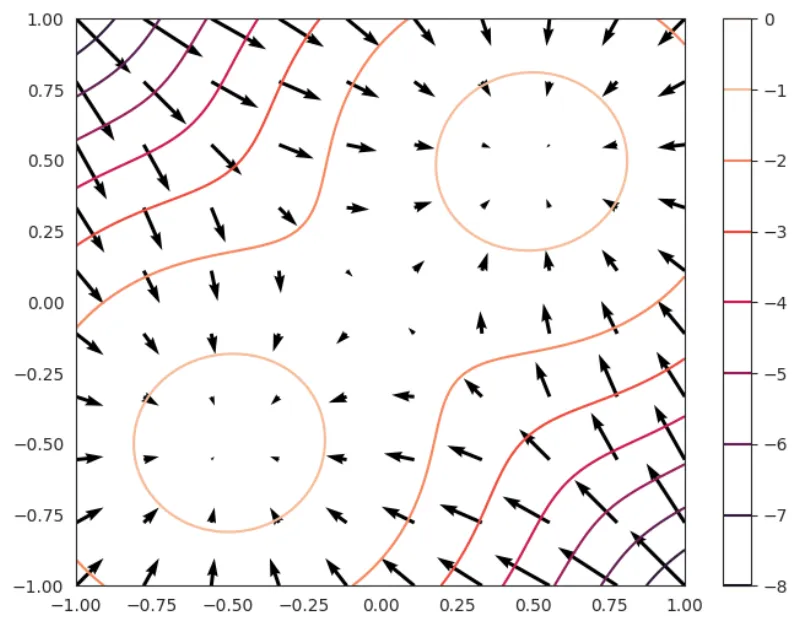
For some very simple models such as mixtures of tractable base models or using
bijectors we don't even need to learn the score function since it's available
to us in closed form. The simplest way to get some intuition for this is to
visualize the the log-probability function \(\log p(x)\) using for
example level-sets and the vector field corresponding to \(s(x)\) in 2 dimensions.
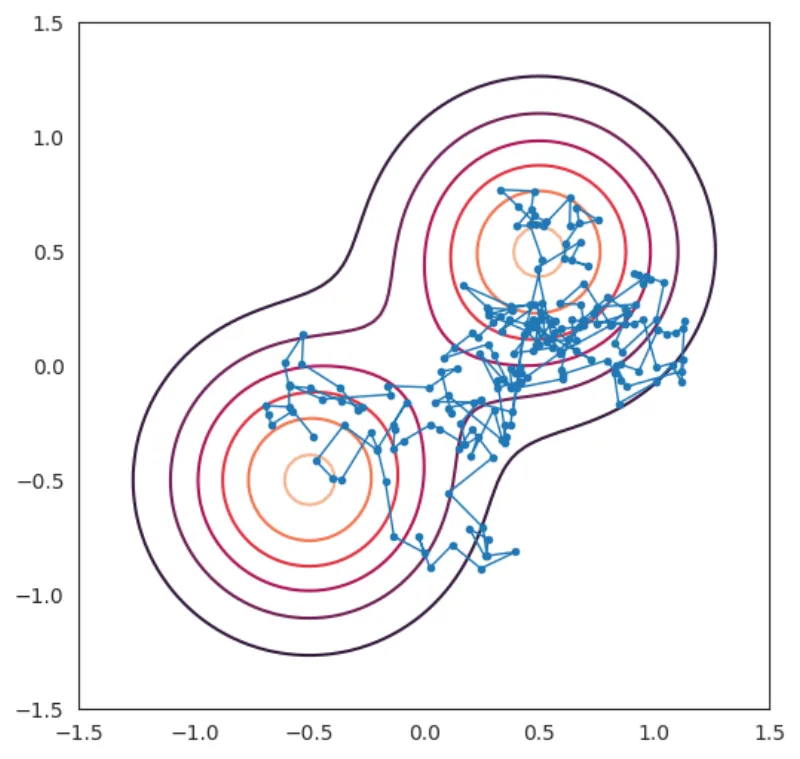
Let's look at the result in this case. To see the path of the particle more
clearly I'll outline the path by simply drawing a line between each point in
result.
Figure 2: Path of a particle following the Langevin dynamics of the mixture model
Finally, let's make a video for goodies. The video is the above plot shown in
time, following the particle according to the Langevin dynamics.
# We will animate this using the FuncAnimation class from matplotlibfrom matplotlib.animation import FuncAnimation
fig, ax= plt.subplots(figsize =(6, 6))
fig, ax= plot_distribution(fig, ax, mixture_model, xlim =( -1.5, 1.5), ylim =( -1.5, 1.5))
# Initialize the line plotline, = ax.plot([], [], marker ='.', linewidth =1.0)
# Initialize the particle positionspositions= result
# Function to update the line plotdefupdate(frame):
# Update the line plot data
line.set_data(positions[:frame +1, 0], positions[:frame +1, 1])
return line,
# Create the FuncAnimationanimation= FuncAnimation(fig, update, frames =len(positions),
interval =100, repeat =False)
# Save using ffmpeg
animation.save( "mog-langevin-dynamics.mp4", writer ="ffmpeg", dpi =200)
The reason we didn't have to learn the score function in Tractable mixture
models was because we restricted ourselves to a distribution with a tractable
score function. In reality this is seldom the case, and even if we could do it
in theory, it may be too computationally expensive to do it directly.
Additionally, If we have a set of points which we interpret as an empirical
distribution then the score function is not even well-defined as there is no
density. We have to resort to learning it in some way.
First, we will use the MNIST dataset where we view an image as a discrete distribution
by normalizing the pixel intensities over the total intensity of all the pixels
in the image. Since each pixel is a value between 0 and 1, we can view this as a
distribution over pixel coordinates. To make this point clear, we assume that
the underlying space is a 2d cartesian square, \(\mathcal{X} = [0, 1]^{2}\) 3,
with each pixel coordinate being normalized to be between 0 and 1. So, an image
is a collection of coordinate pairs and pixel intensity values, in the case of
MNIST which is \(28 \times 28\) we have pixel coordinates \((i, j)\) where \(i,
j \in \{(l + 1/2) / 28\}_{l=0}^{27}\) and the corresponding pixel intensities
\(I(i, j) \in [0, 1]\). With this we have an empirical distribution where
\(\hat{p}(i, j) = I(i, j) / \sum_{i', j'}I(i', j') \propto I(i, j)\).
Behold, the first image to the MNIST training dataset!
# Get an image from mnistimport torchvision
mnist= torchvision.datasets.MNIST( "~/data", download =True)
mnist_images= mnist.data.numpy()
image= mnist_images[0]
image= image.astype( float) / 255.0
defcreate_sample_fn(image):
"""Generate a function that samples from the image distribution"""defsample(num_samples, key):
h, w= image.shape
# Note that random.categorical takes as inputs logits which is why we do not have to normalizereturn jnp.array(
[ divmod(x.item(), w) for x in random.categorical(logits =jnp.log(image.ravel()), key =key, shape =(num_samples,))]
)
return sample
fig, ax= plt.subplots()
im= ax.imshow(image, cmap ="gray")
plt.colorbar(im)
ax.axis( "off")
Let's check the histogram when we sample many times according to the
distribution defined by the image, we should get something similar as the sample
size becomes large. The histogram function will rotate the image though.
Now we set up the training. The architecture here is a combination of things
We use the insights from ( Tancik et al. 2020) which roughly
says that using a pre-processing fourier feature map before the MLP is
helpful for learning high-frequency mappings for coordinate based inputs. We
add a residual connection here, so that the input to the MLP is
jnp.concatenate(f_layer(x), x).
The RFLayer has noise-level specific parameters alpha, beta which
linearly transform the random features and we learn one such transformation
for each noise level (the rest of the architecture is shared, like the MLP
and the original random feature mappings).
Now let's train it. We squint and choose some good hyperparameters and pray to the ML-gods for an auspicious training run (actually I did some hand-tuning).
sigmas= jnp.geomspace(0.0001, 1, 30, endpoint =True)
DEPTH= 3
WIDTH_SIZE= 128
NUM_RF= 256
BATCH_SIZE= 128
STEPS= 5 * 10 ** 4
PRINT_EVERY= 5000
model= Model(in_size =2,
num_rf =NUM_RF,
width_size =WIDTH_SIZE,
depth =DEPTH,
out_size =2,
num_noise_levels =len(sigmas),
key =random.PRNGKey(0))
LEARNING_RATE= 1e -3
optim= optax.adam(LEARNING_RATE)
# The filter spec is a pytree of the same shape as the parameters# True and False represent whether this part of the pytree will be updated# using the optimizer by splitting the parameters into diff_model and static_modelfilter_spec= jtu.tree_map( lambda x: Trueifisinstance(x, jax.Array) elseFalse, model)
filter_spec= eqx.tree_at(
lambda tree: (tree.rf_layer.B_cos, tree.rf_layer.B_sin),
filter_spec,
replace =( False, False),
)
model= train(model, filter_spec, sample, optim, STEPS, BATCH_SIZE, PRINT_EVERY, sigmas, key)
Step 0, Loss 1.0177688598632812
Step 5000, Loss 0.7470076084136963
Step 10000, Loss 0.6700457334518433
Step 15000, Loss 0.6010410785675049
Step 20000, Loss 0.5470178127288818
Step 25000, Loss 0.5063308477401733
Step 30000, Loss 0.47549256682395935
Step 35000, Loss 0.4591177701950073
Step 40000, Loss 0.4523712992668152
Step 45000, Loss 0.43943890929222107
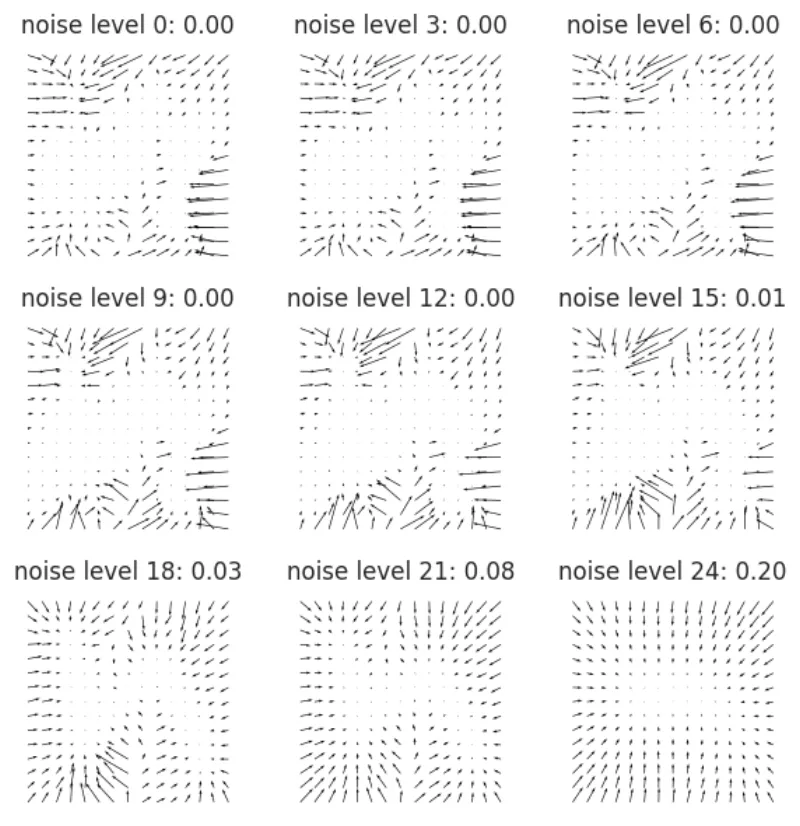
Let's visualize the vector field for this new model by repurposing the plot_logdistribution function to just plot the vector field. Since we don't have an actual density we will not plot the level
Figure 3: The score function for all noise levels used to train the model. It seems like the sweetspot is around 18 (I choose 17 after inspecting all noise levels manually).
Let's see what we have learned. We define the update step (return tuple due to using lax.scan later)
@eqx.filter_jitdefupdate_x(x, z, model, step_size):
g= model(x)
xp1= x + (step_size / 2) * g + jnp.sqrt(step_size) * z
return xp1, xp1
and evolve a particle over many steps, lax.scan simply makes this efficient
Let's look at this. Since we sample so many particles, let's just plot a 2d histogram of this (choosing noise_level_idx being 17 but other indices in the
vicinity should work too). Note that this has a finer resolution than the original mnist images which are \(27 \times 27\)
This was a great way to learn jax and how diffusion works. Looking back I think
it may be overkill to do this on images as distributions as I did above,
learning the distribution directly may be better in this case and faster in this
case. I like the fact that the score model generalizes from the grid points
\((i/27, j/27)_{i, j}^{27}\) to any tuple of points \((i, j)_{i, j \in [0, 1]}\)
which is pretty cool and makes me wonder if you can use this to create a way to
combine images of different resolutions as long as the aspect ratio is the same.
Song, Yang, and Stefano Ermon. 2020. “Generative Modeling by Estimating Gradients of the Data Distribution.” arXiv. http://arxiv.org/abs/1907.05600.
Tancik, Matthew, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. 2020. “Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains.” arXiv. http://arxiv.org/abs/2006.10739.
Feels like there should be some way of looking at this through a
regularization lense where \(\sigma\) takes the role as the regularization
strength in traditional supervised learning such as Ridge Regression.
Although when we convolve the inputs with Gaussians we will have that any point in \(\mathbb{R}^{2}\) will have positive probability, albeit maybe very small.
Jax is basically a compiler for turning python
code and vector operations using the XLA compiler to machine instructions for
different computer architectures. The standard computer architecture we use is the GPU, but there are others, for example
or other specially created hardware which accelerates operations or make them
more efficient in some way. The point is that python is slow and XLA makes this
very fast using techniques such as fusing operations and removing redundant code
and operations. Personally, this feels like a pretty future-proof way of
decoupling how we specify what we want using e.g. python+jax vs how it is made
to run on hardware, here using XLA. It reminds me of how LSP has solved the
decoupling problem for code editing for editors 1. There seem to be even more
specialized hardware being created for e.g. inference of LLMs ( like this which
is one of several LLM inference hardware companies I saw at NeurIPS 2023) so who
knows what funky architectures will become available in the future.
Jax is a reimplementation of the older linear algebra and science
stack for python including numpy and scipy, with a just-in-time compiler and
ways to perform automatic differentiation. To really hammer this home, jax has
reimplemented a subset of both of these packages which seem pretty
feature-complete. The current state of this API can be found in the docs.
The jit function takes a large subset of python together with jax functions
and compile it down to XLA-kernels which are very fast. Below I've done a very
quick benchmark of how jit speeds up matrix-matrix multiplication.
defjax_matmul(A, B):
A @ B
jit_jax_matmul= jit(jax_matmul)
import timeit
n, p, k= 10 **4, 10 **4, 10 **4
A= jnp.ones((n, p))
B= jnp.ones((p, k))
jit_jax_matmul(A, B) # Trace the jit function onceprint(f "jax: {timeit.timeit( lambda: jax_matmul(A, B).block_until_ready(), number =10)} ")
print(f "jax (JIT): {timeit.timeit( lambda: jit_jax_matmul(A, B).block_until_ready(), number =10)} ")
which is about double the speed. The gains are much greater when we jit things
which does not have an already efficient implementation (such as a matmul).
Additionally, this allows us to speed things up which cannot be done without
considerable vectorization effort in numpy or may be outright impossible.
The grad function takes as input a function \(f\) mapping to \(\mathbb{R}\)
and spits out the gradient of that function \(\nabla f\). This can be a very
natural way of working with gradients if you are used to the math.
The function sum_of_squares_dx is the mathematical gradient of
sum_of_squares. The randomness is handled explicitly by splitting the state
(key), read about it here.
The function vmap allows you to lift a function to a batched function,
without having to go through vectorization. For example, if we wanted to batch
the sum_of_squares function we can do this by simply applying vmap
This is pretty powerful: often it's easy to specify the function for a sample
\(x\) but harder to vectorize. For a standard neural network it may be pretty
simple, but imagine something like LLMs, GANs or working with inputs which are
not points, e.g. sets. Additionally, we can use the in_axes argument to batch
in according to different input arguments and ignore others.
defmulti_matmul(A, B, C):
return A @ B @ C
# Batch according to first and third input argument, not secondvmap_multi_matmul= vmap(multi_matmul, in_axes =(0, None, 0))
l, n, p, d, m= 3, 5, 7, 9, 11
A= jnp.ones((l, n, p))
B= jnp.ones((p, d))
C= jnp.ones((l, d, m))
print(vmap_multi_matmul(A, B, C).shape) # l batches of (n, m) -> (l, n, m)
The jax library have some helpful functions for building neural networks. Here
we create parameters and define a prediction function which given a pytree of
parameters and an input outputs the predicted logits. Pytrees is a great thing
about jax where it allow us to intuitively and effectively use not only raw
arrays but also tree-like structures of by composing lists, tuples and
dictionaries with each other and arrays as leaves and map over these as if they
were arrays.
Now we write the helper functions to train this network. In particular we use
the pytree functionality of jax to update the parameters which is a pytree since
it's a list of dictionaries of arrays.
LSP decoupled the implementation of code editing features by allowing the
implementation of a server which editors then used through a frontend. In this
way the frontend implementation relies on a consistent API but does not actually
have to reimplement the server for every editor.
]]>https://isakfalk.com/notes/intro-to-jax.html2024-02-26T10:47:00-05:00Notes for showcasing designIsak Falk
This note is strictly for showcasing how the things that org-mode has
functionality for translates into the actual html output itself. If you don't
know what org-mode is, you can read about it here. I'll basically copy/paste the
source they used there which show most of the functionality and put it here. The
note you are reading right now is the actual output of the build system using
this org-mode file as a source.
Org is a markup language and can be used for all kinds of things, such as italics, bold, strikethrough and underline. It can also combine these styles, such as here. It also has the verbatim and code styles. Additionally we may, if we choose to use the right publishing option, use sub and superscripts, like this or like that. To make a true underline we can use_for this. We should also have access to special symbols: π and also embed latex \(x^2 = \int \sin(y + z)\) or even do equations
We can link to many, many things in different ways. Internally we can link to other headings and also to other files completely (but the links need to be relative for this to work when exporting to html). Finally, we have links to [BROKEN LINK: yt:SzA2YODtgK4] and more, each one handled by their own way internally by org-mode. However, how these are exported vary and all may not be supported.
We can also link to images and style them for example here setting the width to be 300 pixels
Figure 1: This is me
We can also link internal targets globally like this picture of myself, with a true internal link being this . This also works for lists